We live in exciting times. Everywhere we look, we are surrounded by accelerating technological change. Back in the 1980s and 1990s, we considered ourselves lucky when there was one technology wave to hop on. A few of these waves were mainframe technology, relational databases, the advent of the world wide web, to name a few. We now live in an era where it’s hard to keep track of the hot technology trends. IoT, blockchain, microservices, AI/ML, the cloud are just a few of the areas that are on fire today.
Companies like Amazon, Microsoft, and Google do not make it easy to be able to keep up to date with these trends. These companies are engaged on a fierce battle for supremacy to gain mindshare. Technology markets are often a “winner takes all” proposition, and these vendors realize we are just at the beginning stages of the cycle for most of these technologies. Seemingly, almost every day there is a new offering, service of feature enhancement from these providers.
There is one sleeper technology that does not sound as sexy as all the others and doesn’t really even have a popular handle yet. But this technology has the potential to support, amplify, and accelerate all the other technologies listed above and others. It has the potential to ensure that the technologies listed above truly deliver on their promise.
Let’s really get down to fundamentals to understand its impact. There are basic ways to access data. Through a query language like SQL or something similar or via a well-defined set of APIs that abstract these queries. Both approaches are fundamentally different and have distinct advantages and disadvantages.
- Query language – Being able to create queries on the fly enables analysts and data scientists to quickly perform exploratory data analysis and to pivot as the structure of the data or the business requirements change. However, by not having the structure of an API, it is not difficult to introduce bugs and errors into production environments if a structured process is not followed.
- Application Programming Interface API – Having a well-defined API ensures that there is less confusion about what is being sent and received. However, building APIs and writing code take time and they often need to be changed as schemas change and when business needs evolve.
Up until now, when you had one homogenous repository like a database of a set of files that have the same format it was possible to use either of the access approaches listed – a query language or an API.
Once you have more than one data source and especially when these data sources are heterogeneous the choice to use these two options starts disappearing. Up to now, joining or merging two files or tables from two disparate data sets entailed some heavy lifting by having to combine them programmatically using a procedural language like C++, Java, Python, etc.
And that’s where a game-changing technology comes in. Enter Apache Arrow. Apache Arrow enables you to bring in these disparate datasets into memory and allows users to perform traditional SQL query operations on this data. Any file or database that supports the Apache Arrow formats now becomes part of a megastore that can be accessed by any authorized user at scale.
The following diagram illustrates how data can be combined without Apache Arrow:
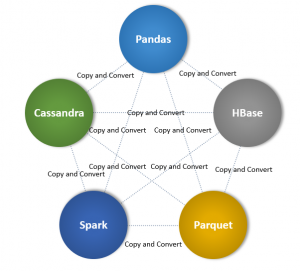
It is immediately apparent from the picture that to create a result set that combines says Spark with Parquet, it is necessary to read, serialize and deserialize from one format to the other so that they can “talk the same language”. This process needs to make a copy of the data first. This could be achieved by reading the data into a memory buffer, then using Parquet’s conversion methods to translate the data. This is needed because Apache Parquet represents data differently from how PySpark used by Spark represents it.
This presents performance problems for several reasons:
- The data needs to be copied and converted. Depending on the data size, the computing resources and time to do so may not be insignificant. Furthermore, all the data needs to be converted before we can start using it. We cannot start performing other computations on the new dataset until the conversion is completed.
- The complete data set being processed hopefully fits into memory. If it doesn’t, the system may crash or the performance will be much slower when accessing the data from disk.
Now let’s look at how Apache Arrow improves this:
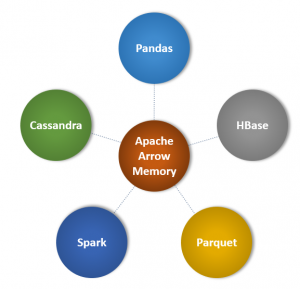
Instead of having to copy and convert the data, Apache Arrow can read and process the data directly. For this to occur, Apache Arrow uses a new file format definition that operates directly on the serialized data. This data can be read directly from disk without having to make a copy into memory, converting, and deserializing the data. Obviously, some of the data still needs to be loaded into memory but not all the data needs to be brought over. Apache Arrow uses memory-mapping techniques to only load the least amount of data needed to perform a given operation.
Traditionally, bring these files into memory into a common format that can be copied, converted, and combined with other data would be computationally prohibitive. However, by using a common format regardless of the source type and optimizing the amount of data that needs to be loaded into memory, much less compute resources are required. However, Apache Arrow offers highly performant connectors from a nice variety of common format and source types like:
Formats Types:
- CSV, TSV, PSV, or any other delimited data
- Apache Parquet
- JSON
- Apache ORC
- Apache Avro
- Hadoop Sequence Files
- Apache and Nginx server logs
- Logs files
External Source Types:
- HBase
- Hive
- Kafka (streaming data)
- MapR-DB
- MongoDB
- Open Time Series Database
- Nearly all relational databases with a JDBC driver
- Hadoop Distributed File System
- MapR-FS
- Amazon S3
These are just a few of the source types that have connectors that can be used with Apache Arrow. At the expense of getting too wonky, some of the reasons Apache Arrow is so performant is because of its columnar format supporting the following key features:
- It can take full advantage of today’s modern hardware with the latest GPUs and CPUs
- It supports zero-copy reads enabling fast data access without incurring serialization overhead
- It supports data adjacency for sequential access (scans)
- It has O(1) (constant-time) random access
- It is SIMD and vectorization-friendly
- It is relocatable without “pointer swizzling”, allowing for true zero-copy access in shared memory
To hopefully drive the point home on the importance of Apache Arrow, let’s look at some of the companies that have committers for the Apache Arrow project. They include:
- Salesforce
- Amazon
- Cloudera
- Databricks
- Datastax
- Dremio
- MapR
In other words, it is a veritable who’s who in technology.
Another technology that complements Apache Arrow is another Apache project – Apache Drill. Apache Drill enables you to perform SQL queries against non-traditional storage like NoSQL and files that do not have a schema. The format and layout of the data are discovered during the query process by Apache Drill. Where is an example of what a query using Apache Drill may look like:
SELECT * FROM e.`employee.json` LIMIT 3; +--------------+------------------+-------------+ | employee_id | full_name | first_name | +--------------+------------------+-------------+ | 1 | Joe Robert | Joe | | 2 | Steve Lloyd | Steve | | 3 | Bill McCaffery | Bill | +--------------+------------------+-------------+
When using traditional databases, the schema of the data has been established long before, and whenever a change is needed to the schema it typically involves a long cycle of making the change in a development environment, testing it, porting over to a staging environment to integrate it with other changes, testing again and finally deploying it in production. With schema-less queries, these changes are not required. As with anything with technology, this is not a silver bullet that solves every problem. But, for many use cases, being able to query data without requiring a schema can greatly reduce the time it takes to begin productively consuming your data and to start getting useful insights from it.
As is the case with many other open source technologies, AWS leverages Apache Arrow and Apache Drill and provides a new service that takes advantage of them. The new service is called Amazon Athena Query Federation.
Initially, Amazon Athena only worked against Amazon S3 files. But with the advent of Amazon Athena Query Federation, data in other storage sources can be accessed and combined with other heterogeneous sources at scale. Athena also leverages connectors (written using AWS Lambda) to perform these queries. Some of the connectors that come “out of the box” with Amazon Athena work with:
- Amazon DynamoDB
- Amazon DocumentDB
- All Amazon RDS flavors
- Many JDBC-compliant databases
- Amazon CloudWatch
In addition, if there is a data source that you want to use and a connector does not exist for it, you can write custom connectors using the Amazon Athena Query Federation SDK.
We cannot emphasize enough how powerful it is to be able to invoke queries across disparate data sources and treat them all like they are part of the same database. SQL statements can be combined with sources from multiple catalogs and can span across multiple data sources regardless of the data format or the data location. Some of the ways that Athena ensure that the queries are performant is to implementing optimizations like:
- Enabling query parallelism
- Filter predicate pushdown
Conclusion
If your workloads invoke a significant volume of data or if your use cases require consolidating data across disparate data sources, it behooves you to explore the unsung technologies highlighted in this piece. Leveraging Amazon Athena Query Federation (which uses Apache Arrow and Apache Drill under the covers) to implement data lakes, data warehouses, data hubs, and data vaults will greatly simplify your development and it will enable you to take better advantage of all the other hot technologies we mentioned at the beginning of the article like AI/ML and IoT.