Machine Learning algorithms can be classified in many ways. One of my favorite classifications is the Pedro Domingo classification using the “Five tribes”. Today I will be using a more basic and traditional classification. This classification method is as follows:

- Supervised learning
- Unsupervised learning
- Reinforcement learning
Supervised learning
With supervised learning, you have a defined target, value or class to you want to predict. In other words, the “answer” to your prediction exists in a predefined set of possible answers.
Supervised learning uses a variety of techniques which all share the same principles:
The training dataset contains inputs data (your predictors) and the value you want to predict. The prediction can be a number, a classification or a binary value.
The model will use the training data to establish a connection between the input and the output. The underlying idea is that the training data can be generalized and that the model can be used on new “unseen” data with a certain degree of accuracy.
Examples of supervised learning
- You want to determine if an email is “spam” or “not spam”
- Given an incoming insurance claim, you want to determine what the “next best action” is (e.g., pay it off automatically, send it to a senior claim adjuster, give it to a junior claim adjuster, etc.)
- You want to predict what the price of a stock will be tomorrow.
- Image recognition
- Speech recognition
- Forecasting
Supervised learning algorithms
- Linear and logistic regression
- Support vector machine
- Naive Bayes
- Neural networks
- Gradient boosting
- Classification trees and random forest
Unsupervised learning
In this case, we don’t have labels ahead of time for our data. We are looking for patterns or groupings in the data. For example, you may want to cluster your customers according to the type of products they order, how often they purchase your product, their last visit, etc. Instead of creating classification manually ahead of time, unsupervised machine learning will automatically create the clusters.
On the other hand, unsupervised learning does not use output data (at least output data that are different from the input). Unsupervised algorithms can be split into three distinct categories:
- Clustering algorithm, such as K-means, hierarchical clustering or mixture models. These algorithms try to discriminate and separate the observations in different groups.
- Dimensionality reduction algorithms (which are mostly unsupervised) such as PCA, ICA or autoencoder. These algorithms find the best representation of the data with fewer dimensions.
- Anomaly detections to find outliers in the data, i.e. observations which do not follow the data set patterns.
Most of the time unsupervised learning algorithms are used to pre-process the data, during the exploratory analysis or to pre-train supervised learning algorithms.
Reinforcement learning
The third classification is reinforcement learning. In this case, you want to attain an objective. For example, you want to find the best strategy to win a game with specified rules. Once these rules are specified, reinforcement learning techniques will play this game hundreds, thousands and maybe millions of times to find the best strategies.
Reinforcement learning algorithms try to find the best ways to earn the greatest reward. Rewards can be winning a game, earning more money or beating other opponents. The latest state-of-art results in many domains are on par and in some cases, surpass human abilities.
Reinforcement learnings algorithms follow these steps:
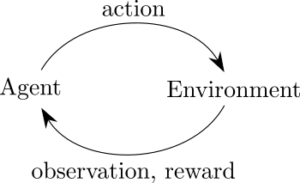
It assumes that there is an agent that is situated in an environment. At each step, the agent takes an action, and it receives an observation and reward from the environment. An RL algorithm seeks to maximize the agent’s total reward, given a previously unknown environment, through a learning process that normally involves lots of trial and error.
An important point in reinforcement learning is that the intermediate steps might look like negative or “dumb” moves but they are done with the final goal in mind. An example from chess might be sacrificing a rook to win the game.
Examples of reinforcement learning:
- The most advanced Go player is currently a computer. You can find a paper explaining the system here.
- Financial Portfolio Management
- DNA fragment assembly
Conclusion
Having a firm grasp on when to use each of these types of algorithms is critically important when setting up your models. The type of learning will be defined by the type problem you are trying to solve and is intrinsic to the goal of your analysis.
I am always looking for new article ideas. If there is a topic you are interested in learning more about, send me your thoughts and feedback and I’ll do my best to research it and help you understand it. In the meantime, happy coding!