A common catchy phrase making the rounds lately is “data is the new oil”. There is a lot of truth in it in many regards. Up until 10 years ago or so, storage costs made it prohibitive to store more than a few years-worth of enterprise and personal data. It was not uncommon for most application logs to be purged on a regular schedule. Moore’s Law has been doing what it does regarding storage costs to the point that very little gathered information is ever purged. Google lets you store an insane number of pictures and documents for free, Facebook has been on the news lately because of the vast amounts and type of data that they gather and store on their users and it would be sacrilege for a company like Amazon to discard the shopping history of their buyers.

For storage device makers the race to make storage affordable is over and the result is that nobody won. Around 1980 the cost of one gigabyte was in the order of $500,000. That same gigabyte can now be stored for a few cents or even less depending on the storage medium. The cost has become a rounding error.
In addition, we have become much more adept at extracting value from this data. Technologies to aggregate, sift and analyze this data has gotten exponentially better and faster.
Actually, the phrase “data is the new oil” is not that new. Clive Humby, a UK mathematician and an architect with Tesco’s Clubcard is credited with coining the term back in 2006. And it has been often repeated ever since by many technology luminaries. The analogy is not perfect, but the important takeaway is people can and have been fired for losing this new valuable resource.
The rest of the thrust of this article is an attempt at explaining why this is so. The reason can be summed up in one sentence: “Data is the new code”
Data is the new code
Traditionally software engineering has required a couple input ingredients to produce an output:
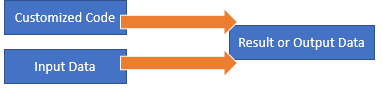
More recently, in the machine learning and artificial intelligence realm, there is no need to continuously change the code. The same code that can extract insights from one dataset can be used to process a completely different dataset. For example, you might you use gradient boosting, random forest or a deep neural net to analyze stocks, e-commerce data, genomic data, MRI images, etc. Notice the diversity of the input data and how it cuts across so many examples and industries. We might tweak the model hyperparameters during training but the algorithm used is the same across datasets. Our flow now becomes:

Essentially the input data is now the “code” and the only time the model changes is when we come up with an optimization of the code to make it faster or more precise. This insight is a game changer because it forces us to shift our attention away from being coders and bit twiddlers and turns our attention to find data in untraditional places to feed these models and to come up with interesting questions to ask from that data. When we think of data, we might picture structured or unstructured files and we might even think of images as other types of data. In reality, anything that exhibits some degree of heterogeneousness is data. For example, a string consisting of nothing but ones cannot be thought of as data (or maybe it’s data with a very boring message), but a string that consists of zeros and ones now become heterogeneous and can potentially contain a message (and maybe even an interesting one).
| Every dataset contains a story, it’s up to us to give it a voice |
The rest of this article mentions a few of the traditional and obvious sources for datasets. Followed by a more fun exercise–trying to identify and highlight some unconventional datasets that might not have been traditionally considered traditional “data”.
Traditional Datasets
- Stock and Economic Data
- Retail sales data
- Online and social media behavior
- Application user and error logs
- Motion sensor data
- Video Feeds
Unconventional datasets
Genomic data – The ability to sequence DNA provides researchers with the ability to “read” the genetic blueprint that directs all the activities of a living organism. To provide context, the central dogma of biology is summarized as the pathway from DNA to RNA to Protein. DNA is composed of base pairs, based on 4 basic units (A, C, G, and T) called nucleotides: A pairs with T and C pairs with G. DNA is organized into chromosomes and humans have a total of 23 pairs.
Chromosomes are further organized into segments of DNA called genes which make or encode proteins. The sum of genes that an organism possess is called the genome. Humans have roughly 20,000 genes and 3 billion base pairs. As you can imagine, this makes for a very interesting input data set which is ripe with possibilities for drug discovery and individualized patient diagnoses.
Medical data – Specifically, in the diagnosis stage, a substantial proportion of the AI literature analyses data from diagnosis imaging, genetic testing, and electrodiagnosis. For example, Jha and Topol urged radiologists to adopt AI technologies when analyzing diagnostic images that contain vast data information.13 Li et al studied the uses of abnormal genetic expression in long non-coding RNAs to diagnose gastric cancer.14 And, Shin et al developed an electrodiagnosis support system for localizing neural injuries.15
Chemical compound databases – The biopharmaceutical industry is looking toward AI/ML to speed up drug discovery, cut research and development costs, decrease failure rates in drug trials and eventually create better medicines. Against this backdrop, The 2nd annual SMi’s Drug Discovery conference took place in London on 21 and 22 March 2018. There they discussed the role of artificial intelligence SMi’s in the Drug Discovery process. Leading experts from ETH Zurich, Exscientia, Benevolent AI and AstraZeneca spoke on the subject. Professionals from the field discussed Artificially Intelligent Drug Design, Transforming Small Molecule Drug Discovery Using Artificial Intelligence, Disrupting Drug Discovery with AI and Machine Learning for Smarter Drug Discovery. This is just one example of the research in this sub-field.
Mouse and keyboard strokes as data – Robotic process automation (RPA) is the application of technology that allows employees in a company to configure computer software or a “robot” to capture and interpret existing applications for processing a transaction, manipulating data, triggering responses and communicating with other digital systems.
Any company that uses labor on a large scale for general knowledge process work, where people are performing high-volume, highly transactional process functions, will boost their capabilities and save money and time with robotic process automation software.
Just as industrial robots are remaking the manufacturing industry by creating higher production rates and improved quality, RPA “robots” are revolutionizing the way we think about and administer business processes, IT support processes, workflow processes, remote infrastructure and back-office work. RPA provides dramatic improvements in accuracy and cycle time and increased productivity in transaction processing while it elevates the nature of work by removing people from dull, repetitive tasks.
We are not quite there yet, but it is not impossible to imagine a scenario where this “robot” observes a human perform a repetitive task for a determined period and can take over after learning the steps learned from observing the process.
Brainwave activity – New research from scientists in the University of Toronto Scarborough are using EEG data (“brainwaves”) to reconstruct images of faces shown to subjects. In other words, they’re using EEG to tap into what a subject is seeing.
With another research group with the Toyohashi University of Technology in Japan, an electroencephalogram (EEG) was used to monitor people’s brain waves while they spoke. This system was partially effective with a 90 percent success rate when trying to recognize numbers from zero to nine and it had a 61 percent rate for single syllables in Japanese.
This group issued a statement about their research saying: “Our system showed that an effective device to read people’s thoughts and relay them to others is possible in the near-future”.
Sentiment analysis from voice files – There is starting to be some research using an AI personal assistant that chats with you on a day to day basis to determine your mood to see if you are in a depressed state and perform or recommend actions as appropriate. Similar research is starting to emerge in the area of addiction and drug and alcohol abuse.
Speaker recognition and identification from audio files – While no authentication system is perfect voice biometrics is increasingly being used as an additional authentication factor to identify and authorize users.
Unstructured text – Initial attempts to master Natural Language Understanding (NLU) and Natural Language Translation (NLT) in previous decades were rule-based traditional approaches. The results are in. The state of the art when it comes to NLU and NLT use deep neural networks and other unsupervised methods. It is possible that these systems might be enhanced by contextual real-world rules but human-like performance can now be achieved using only machine learning algorithms.
Food ingredients – Determine food quality (for example, identifying if a wine is fake or not) or if the food supply has been tainted.
Conclusion
I would love to get your feedback on other examples that you come up with that we might not traditionally think of a “dataset” that can be used as input to feed our models. Add your ideas below.