We have come a long way since the days of the ENIAC machine. It has been 75 years since its creation. Along the way, there have been a few inflections points that have made a huge impact on the development of computers and technology. I guess we can consider the ENIAC the first mainframe, and mainframes ruled the world up until the 1980’s when Apple IIe’s, Mac’s and PC’s started to emerge. As desktop and laptop computers proliferated, we started connecting these computers. First in the form of LAN’s and WAN’s and later through the internet. This revolution took hold throughout the 90’s and famously took a pause when the internet bubble burst in March 2000. Now the next “big thing” or “wave” is less clear to discern. Some people will say it’s Social Media. Others will argue it’s mobile devices and the “internet of things” (IOT). Some folks will argue that it’s blockchain.
All these trends have merit as next wave, but I believe what we are experiencing is not just one important trend, but the convergence of three huge waves that are all crashing into each other and feeding each other. These waves are:
- Big Data
- Cloud Computing
- Artificial Intelligence
Let’s go deeper into them one at a time and see how they are interrelated.

Big Data
This term gets thrown around quite a bit and many times without a thorough understanding. This is one of my favorite quotes on the subject:
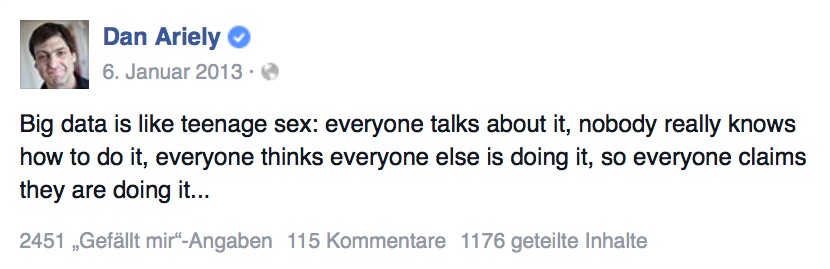
There are many definitions of big data but in simple terms, big data datasets are those that are too big to be processed by “traditional” data-processing methods. One quick example is Google. We use Google almost subconsciously now, but if we stop to think for a second, it is a veritable miracle that we can access the billions of documents and get the most relevant results in a few milliseconds. This would have never been possible using a traditional database architecture. In fact, the technology powering Google planted the seeds that powered the big data revolution[1]. In simple terms, the breakthrough that enabled the big data era is the ability to “scale out” systems instead of having them “scale up”. Let’s explain this further. Using a traditional SQL architecture, whenever you reached the hardware limits, the normal solution would be to buy a bigger machine with a more powerful CPU’s or more CPUs and more memory. You would then have to transfer your application and data to the new system which is a cumbersome process. With the advent of new technologies like Hadoop, Spark, and NoSQL instead of having to need a “bigger boat”, we can bring another machine to share the load, or two or an army of machines, each sharing part of the load.

Cloud Computing
This is another term that gets thrown around a lot by many people many times without having a firm grasp of its exact meaning. Even the term itself connotes ethereal images of machinery in the sky surrounded by rainbows and unicorns. I will again try to define it in the simplest of ways. At its core, a cloud computing is the outsourcing of an enterprise’s hardware and software infrastructure. Instead of having your own data center, you are borrowing someone else’s. This has many advantages among them, the economies of scale that come from the cloud provider buying the equipment in bulk. But the most arguably important benefit that comes from cloud computing is the ability to “scale down”. With cloud computing, you are not buying the equipment you are leasing it. Granted equipment leasing has been around for a long time but not at the speed that cloud computing provides. With cloud computing, it is possible to spin up an instance within minutes, use it for a few hours, minutes or even seconds and then shut it down and you would only pay for the time you used it. Furthermore, with the advent of “serverless” computing such as AWS Lambda services, we don’t even have to worry about provisioning the server and we can just call a Lambda function and pay by the function call. One example to drive the point home, the latest P3 instances available for use with AWS Sagemaker[2] Machine Learning service can be used for less than $5.00/hr[3]. This might sound like a high price to pay for rent one computer but a few years ago we would have had to pay millions of dollars for a super-computer with similar capabilities. And importantly after our model is trained we can shut down this instance and deploy our inference engine into more appropriate hardware. The idea of being able to “scale down” is often referred as “elasticity” and it is a breakthrough just as important as the ability to “scale up”.

Artificial Intelligence
The confusion surrounding Big Data and Cloud pales in comparison to the fog of bewilderment hovering over the field of Artificial Intelligence. Killer robots are not coming to get us anytime in the near-future and computers are still some ways away from being truly autonomous. The classical definition of Artificial Intelligence (AI) might go something along the lines of “machines being able to mimic human intelligence and/or behavior”, but I prefer a simpler and maybe more imprecise definition. Artificial Intelligence is just another wrench in the technologist’s toolbox. Computers have long displayed some characteristics that mimic and far surpass human performance. Take number multiplication as an example, computers have long ago surpassed us in their ability to perform arithmetic, yet we don’t think of this computer activity as “Artificial Intelligence” because it’s a very simple problem to solve for a computer. Instead of getting caught up in this debate, let’s just instead use the techniques that have come up from the field of AI. Be it Neural Networks (NN) or Natural Language Understanding (NLU), they are just another technique to solve problems. AI might not always be the answer. In some instances, Graph Databases, Crowd Sourcing (Natural Intelligence), or traditional statistics might be a better answer to a specific problem.
Having said all this there is no denying that recent advances in Convolutional Neural Networks[4], Recurrent Neural Networks[5], and Reinforcement Learning [6]. In addition, we are at the beginning of the first inning and the pace of development keeps on accelerating.
Putting it all together
These three waves are powerful in their own right, but their true power comes from the symbiotic relationship between all three. Experiments that a few years ago would be cost prohibitive or even impossible are now within reach. We can know spin up a cluster of hundreds of nodes to create powerful models and then shut them down after the model has been created and then move the model to a different instance to serve as an inference engine. Services such as AWS Kinesis Firehose allows processing of an enormous amount of data even if it’s coming in at a high rate of speed. In addition, the latest incarnations of the latest AI/ML algorithms are orders of magnitude faster than the predecessors just a few days ago. Having this three-pillar foundation has been the basis for many breakthroughs in the last few years in computer applications across many industries. I won’t list these advances here and instead, we will explore them in an upcoming article. Cheers.